Aritalab:Lecture/NetworkBiology/Contact Process
m (→コンタクトプロセス) |
m (→SIR model) |
||
| Line 101: | Line 101: | ||
==SIR model== | ==SIR model== | ||
| − | <math>S(t) + I(t) + R(t) = 1</math> | + | <math>S(t) + I(t) + R(t) = 1\ </math> が成立します。 |
===ネットワークを考慮しない場合=== | ===ネットワークを考慮しない場合=== | ||
| − | 時間<math>\Delta t</math>の間に感染者は<math>\mu</math>の確率で治癒し、健康人が<math>\lambda I(t)</math> | + | 時間 <math>\Delta t</math> の間に感染者は <math>\mu</math> の確率で治癒し、健康人が <math>\lambda I(t)\ </math> の確率で感染するとします。 |
<math> | <math> | ||
| Line 114: | Line 114: | ||
</math> | </math> | ||
| − | + | 十分時間が経過した後の定常状態において十分量の感染しない健康人 <math>R(t)\ </math> が生じるためには、初期 (<math>t\sim 0\ </math>) は ''I'' が少ないけれども次第に病人が増えて蔓延し、その後終息して ''R'' に変化しないといけません。 | |
<math> | <math> | ||
| − | + | \frac{d I(0)}{dt} = \lambda S(0) I(0) - \mu I(0) > 0 | |
| − | \frac{d I(0)}{dt} | + | </math> |
| − | \frac{\lambda}{\mu} | + | |
| − | + | この式から | |
| + | |||
| + | <math> | ||
| + | \frac{\lambda}{\mu} = \frac{1}{S(t= 0)} | ||
</math> | </math> | ||
| − | + | が重要なポイントです。つまり感染率 <math>\lambda</math> が治癒率 <math>\mu</math> を超える場合は病人の割合が増加し、逆の場合は病人が減少する一方になります。 | |
SISモデルと同様、今後は一般性を失わずに<math>\mu=1</math>とおく。 | SISモデルと同様、今後は一般性を失わずに<math>\mu=1</math>とおく。 | ||
| Line 129: | Line 132: | ||
===一般のネットワークの場合=== | ===一般のネットワークの場合=== | ||
| − | 次数分布のみを考慮することにし、前出の式を次数''k'' | + | 次数分布のみを考慮することにし、前出の式を次数 ''k'' に限定して考えます。 |
<math> | <math> | ||
| Line 135: | Line 138: | ||
</math> | </math> | ||
| − | + | SISモデルとの違いは、いちど感染した頂点が S に戻らず R になる点です。 | |
| − | 関数<math>\Theta</math> | + | 関数 <math>\Theta\ </math> を求めるには、S に隣接する頂点が I である割合を考えます。 |
| − | + | ある頂点が I のとき、必ずその頂点を感染させる原因となる頂点 (IかR) がまわりに存在します。 | |
| − | よって、隣接頂点の次数分布を<math>kp(k)/\langle k \rangle</math>の代わりに、大雑把に<math>(k-1)p(k)/\langle k \rangle</math> | + | よって、隣接頂点の次数分布を <math>kp(k)/\langle k \rangle\ </math> の代わりに、大雑把に <math>(k-1)p(k)/\langle k \rangle\ </math>と見積もってみます。 |
| − | + | (ここで明らかに、SISモデルの感染力 > SIRモデルの感染力ですが、その差が次数1個分という論理的な必然性はありません。少なくとも 1 点は I か R であるという仮定です。) | |
<math> | <math> | ||
| Line 154: | Line 157: | ||
</math> | </math> | ||
| − | ここから、臨界確率<math>\lambda_c = \frac{\langle k \rangle}{\langle k^2 \rangle - \langle k \rangle}</math> | + | ここから、臨界確率<math>\lambda_c = \frac{\langle k \rangle}{\langle k^2 \rangle - \langle k \rangle}</math>となります。 |
| + | つまり、SISモデルとSIRモデルは基本的に結果が変わりません。 | ||
==SIRモデルとパーコレーション== | ==SIRモデルとパーコレーション== | ||
Revision as of 09:54, 23 June 2011
| Wiki Top | Up one level | レポートの書き方 | Arita Laboratory |
|
コンタクトプロセス
感染症モデルでネットワーク構造を考慮したものをコンタクトプロセスと呼びます。 それぞれの状態の割合を
- S susceptible (健康状態)
- I infected (感染状態)
- R recovered (治癒状態)
と書く。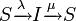 の場合をSISモデルと呼び、
の場合をSISモデルと呼び、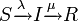 の場合をSIRモデルと呼びます。
の場合をSIRモデルと呼びます。
SIS model
感染者 (infected) の割合を 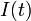 , 健康人 (susceptible) の割合を
, 健康人 (susceptible) の割合を 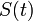 で表します。
で表します。
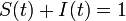
ネットワークを考慮しない場合
時間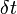 の間に感染者は治癒率
の間に感染者は治癒率 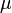 で治癒し、健康人が感染率
で治癒し、健康人が感染率 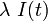 で感染するとします。
で感染するとします。
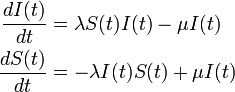
十分時間が経過した後の定常状態を考えると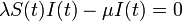 を式変形して
を式変形して
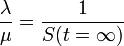
つまり感染率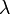 が治癒率を超える場合は健康人の割合が減少し(病人が必ず残る)、感染率のほうが小さい場合は
が治癒率を超える場合は健康人の割合が減少し(病人が必ず残る)、感染率のほうが小さい場合は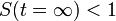 のために病人はゼロになります。
感染症が蔓延するか否かの分かれ目(臨界値)は、個々人の平均的な治癒率よりも感染力が強いかどうかに依存します。
のために病人はゼロになります。
感染症が蔓延するか否かの分かれ目(臨界値)は、個々人の平均的な治癒率よりも感染力が強いかどうかに依存します。
以降、とは定数倍(正規化)すれば片方を消せるので、一般性を失わずに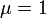 とおきます。
とおきます。
一般のネットワークの場合
次数分布のみを考慮することにし、前出の式を次数 k に限定して考えましょう。次数 k の頂点たちの中における感染者数は
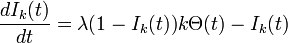
ここで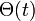 は、辺の接続先に感染者がいる期待値です。定常状態のとき、
は、辺の接続先に感染者がいる期待値です。定常状態のとき、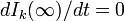 なので感染者の割合は
なので感染者の割合は
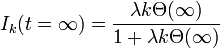
ここで、定常状態における 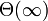 を求めましょう。
次数 k の頂点から出る辺の先にある頂点の次数分布は
を求めましょう。
次数 k の頂点から出る辺の先にある頂点の次数分布は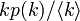 ですから
ですから
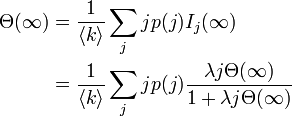
これを について閉じた式にできれば感染率 に対する感染者の期待値を解析的に求められますが、容易ではありません。ここで求めたいのは臨界値を与える だと考えて、右辺と左辺の関係に注目します。
について閉じた式にできれば感染率 に対する感染者の期待値を解析的に求められますが、容易ではありません。ここで求めたいのは臨界値を与える だと考えて、右辺と左辺の関係に注目します。
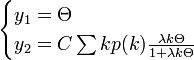
という連立方程式の解を考えます。下の曲線は で定義され、
で定義され、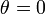 が解の一つである。また
が解の一つである。また 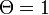 のときに
のときに 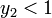 です。微分するとその値は正、つまり単調増加です。
です。微分するとその値は正、つまり単調増加です。
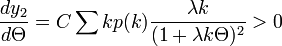
この曲線と、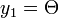 という曲線の交点が(存在するなら)もう一つの解になります。
連立方程式が
という曲線の交点が(存在するなら)もう一つの解になります。
連立方程式が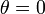 以外にも解を持つかどうかの分岐点は
以外にも解を持つかどうかの分岐点は 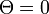 における微分値(傾き)が 1 以上になるかどうかです。
における微分値(傾き)が 1 以上になるかどうかです。
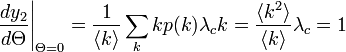
ここから、臨界確率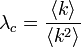 が導かれます。
が導かれます。
具体例
- 次数分布がポアソン分布の場合
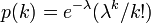 のとき
のとき
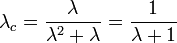
- 次数分布が指数分布の場合
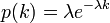 のとき
のとき
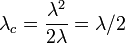
- 次数分布がべき分布の場合
グラフ上のパーコレーションと同じになります(ここを参照)。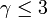 のときに
のときに 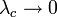 となり、必ず蔓延します。
となり、必ず蔓延します。
SIR model
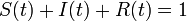 が成立します。
が成立します。
ネットワークを考慮しない場合
時間 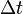 の間に感染者は の確率で治癒し、健康人が
の間に感染者は の確率で治癒し、健康人が 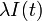 の確率で感染するとします。
の確率で感染するとします。
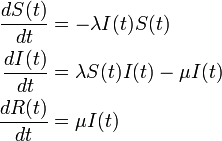
十分時間が経過した後の定常状態において十分量の感染しない健康人 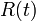 が生じるためには、初期 (
が生じるためには、初期 (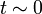 ) は I が少ないけれども次第に病人が増えて蔓延し、その後終息して R に変化しないといけません。
) は I が少ないけれども次第に病人が増えて蔓延し、その後終息して R に変化しないといけません。
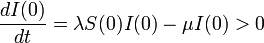
この式から
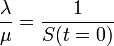
が重要なポイントです。つまり感染率 が治癒率 を超える場合は病人の割合が増加し、逆の場合は病人が減少する一方になります。
SISモデルと同様、今後は一般性を失わずにとおく。
一般のネットワークの場合
次数分布のみを考慮することにし、前出の式を次数 k に限定して考えます。
SISモデルとの違いは、いちど感染した頂点が S に戻らず R になる点です。
関数 を求めるには、S に隣接する頂点が I である割合を考えます。
ある頂点が I のとき、必ずその頂点を感染させる原因となる頂点 (IかR) がまわりに存在します。
よって、隣接頂点の次数分布を 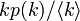 の代わりに、大雑把に
の代わりに、大雑把に 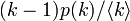 と見積もってみます。
(ここで明らかに、SISモデルの感染力 > SIRモデルの感染力ですが、その差が次数1個分という論理的な必然性はありません。少なくとも 1 点は I か R であるという仮定です。)
と見積もってみます。
(ここで明らかに、SISモデルの感染力 > SIRモデルの感染力ですが、その差が次数1個分という論理的な必然性はありません。少なくとも 1 点は I か R であるという仮定です。)
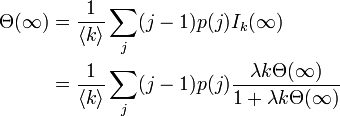
この式が以外にも解を持つかどうかの分岐点は
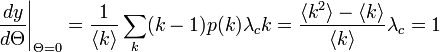
ここから、臨界確率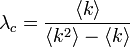 となります。
つまり、SISモデルとSIRモデルは基本的に結果が変わりません。
となります。
つまり、SISモデルとSIRモデルは基本的に結果が変わりません。
SIRモデルとパーコレーション
SIRモデルはいったん感染すると後はRに移動するだけである。したがって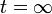 における最終結果は各辺について一回ずつ感染か非感染かを評価するパーコレーションと変わらない。
における最終結果は各辺について一回ずつ感染か非感染かを評価するパーコレーションと変わらない。
このように、頂点ではなく辺に活性、非活性を割り当てる方式をボンド・パーコレーションと呼ぶ。