Aritalab:Lecture/NetworkBiology/Barabasi-Albert Model
m |
|||
| Line 1: | Line 1: | ||
{{Lecture/Header}} | {{Lecture/Header}} | ||
| − | == | + | ==Scale-free性== |
| + | ネットワークの頂点に接続する辺の数を次数といい、全頂点のなかで次数 ''k'' の頂点の占める割合を ''p(k)'' と書きます。 | ||
| + | ネットワークがスケールフリーであるとは次数の分布がべき則に従うことを意味し、式で書くと | ||
| + | <math>p(k) \propto k^{-\gamma}</math> | ||
| + | になります。 | ||
| − | + | この定義は1999年の論文 Barabási A-L, Albert R "Emergence of Scaling in Random Networks" [http://www.sciencemag.org/content/286/5439/509.abstract ''Science'' 286(5439):509-512] をきっかけに広まりました。 | |
| − | + | ||
| − | + | ||
| − | + | 自然界にはべき則が普通に見られ、以下の例がよく知られています。(この表におけるL, Cの意味は[[Aritalab:Lecture/NetworkBiology/Link_Analysis|リンク解析]]の項を参照。) | |
| − | + | ||
| − | + | ||
{| class="wikitable" | {| class="wikitable" | ||
! Network (size) || <math>\gamma</math> || ''L'' || ''C'' || | ! Network (size) || <math>\gamma</math> || ''L'' || ''C'' || | ||
|- | |- | ||
| − | | | + | | インターネット (1.5 x 10<sup>5</sup>) || <math>\gamma_{in}=2.1, \gamma_{out}=2.7</math> || 3.1 || 0.11 || Barabasi and Albert (1999) |
|- | |- | ||
| − | | | + | | 部分的インターネット (3000-6000) || 2.16 || 3.7 || 0.18-0.3 || Faloutous et al. (1999) |
|- | |- | ||
| − | | | + | | 映画俳優の共演関係 (2.2 x 10<sup>5</sup>) || 2.3 || 3.7 || 0.79 || Watts and Strogatz (1998) |
|- | |- | ||
| − | | | + | | PubMedデータベースの共著関係 (1.5 x 10<sup>6</sup>) || ? || 4.6 || 0.066 || Newman (2000, 2001) |
|} | |} | ||
| − | + | べき則やそれを生み出すメカニズムの解析は最近始まったものではありません。科学界ではおよそ50年周期で話題になってきました。べき則を示す有名な例として、ジップの法則、パレートの法則などがあります。 | |
| + | * 20世紀初頭 | ||
| + | ** Pareto, V. (1896, 1897) Cours d’economie politique. Reprinted as a volume of Oeuvres Complètes (Droz, Geneva, 1896, 1965). Pareto, V. Cours d’Economique Politique (Macmillan, Paris, 1897) 所得の分布がべき則に従うことを示す | ||
| + | ** Yule, G. (1924) A mathematical theory of evolution, based on the conclusion of Dr. J.C. Willis. F.R.S. Phil. Trans. R. Soc. Lond Ser. B 213, 21–87 優先的選択のメカニズムを示す | ||
| + | * 20世紀半ば | ||
| + | ** Zipf, G.K. (1949) Human Behavior and the Principle of Least Effort, Addison-Wesley 単語の頻度分布がべき則に従うことを示す | ||
| + | ** Simon, H.A. (1955) On a class of skew distribution functions. Biometrika 42, 425–440 乗算過程が漸近的にべき則に従うことを示す | ||
| + | * 21世紀初頭 | ||
| + | ** Barabási A-L, Albert R (1999) これまでの研究をネットワークの言葉に置き換える | ||
| + | |||
| + | またべき則に近い形である対数正規分布とべき則の関係についても多くの研究がなされました。 | ||
| + | * 乗算過程による対数正規分布の一般性 | ||
| + | ** Kapteyn, J.C. (1903) Skew frequency curves in biology and statistics in Astronomical Laboratory, Noordhoff, Groningen | ||
| + | ** Gibrat, R. (1931) Les Inegalites Economiques, Libraire du Recueil Sirey, Paris | ||
| + | * 乗算過程がべき則を生むメカニズム | ||
| + | ** Kesten, H. (1973) Random difference equations and renewal theory for products of random matrices. Acta Mathematica CXXXI, 207–248 | ||
| + | ** Reed, W.J. and Hughes, B.D. (2002) From gene families and genera to incomes and internet file sizes: why power-laws are so common in nature. Phys. Rev. E 66, 067103 | ||
| + | |||
| + | ==Barabási-Albert Model== | ||
| + | Barabási, Albertがネットワークの成長モデルとして提唱したのは以下の過程です。(正確には初期条件が異なるが本質は同じ。) | ||
| + | # 時間ステップ1において<math>m</math>本の辺で結ばれた2頂点からスタートする。 | ||
| + | # 単位時間毎に頂点を1つずつ追加し、既に存在する頂点と<math>m</math>本の辺でつなぐ。<br/>新しい辺はそれぞれ確率<math>\textstyle p_i = k_i / \sum_j k_j</math> (ここで<math>k_i</math>は頂点''i''の次数) で接続先を決定する。 | ||
| + | |||
| + | この過程は優先的選択(preferential attachment)と呼ばれ、一般に''rich gets richer''メカニズムなどともいわれます。 | ||
| + | |||
==べき則のパラメータ<math>\gamma</math>について== | ==べき則のパラメータ<math>\gamma</math>について== | ||
| − | + | BAモデルから<math>\gamma = 3 </math>を簡単に導出できます。 | |
| − | 初期条件として2頂点が<math>m</math>本のリンクで結ばれている場合、<math>t</math>時間後には頂点数<math>t+1</math>、辺数<math>mt</math> | + | 初期条件として2頂点が <math>m</math> 本のリンクで結ばれている場合、<math>t</math>時間後には頂点数<math>t+1</math>、辺数 <math>mt</math> です。 |
| − | + | 頂点 ''i'' の次数 <math>k_i</math> は時間が経つと単調増加します。ここで、次数を <math>k_i(t)</math> という連続関数として考えてみます。頂点 ''i'' の次数は単位時間あたり次数 <math>k_i</math> に比例して増加するので | |
<center> | <center> | ||
<math>\frac{\partial k_i}{\partial t} = m \frac{k_i}{\sum_j k_j} = \frac{k_i}{2t}</math> | <math>\frac{\partial k_i}{\partial t} = m \frac{k_i}{\sum_j k_j} = \frac{k_i}{2t}</math> | ||
</center> | </center> | ||
| − | これを解くと<math>\textstyle k_i(t) = m(t/t_i)^{1/2}</math>、 | + | これを解くと <math>\textstyle k_i(t) = m(t/t_i)^{1/2}</math>、 |
| − | ただし<math>t_i</math>は頂点<math>i</math>が追加された時間で<math>k_i(t_i)=m</math> | + | ただし <math>t_i</math> は頂点 <math>i</math> が追加された時間で <math>k_i(t_i)=m</math> となる値です(初期条件)。 |
| − | これを式変形すれば、頂点の次数がある値<math>x</math>になる時間は<math>t=t_i(x | + | これを式変形すれば、頂点の次数がある値 <math>x</math> になる時間は <math>t=t_i(\frac{x}{m})^2</math> であることがわかります。 |
| − | + | ||
| + | 頂点の次数分布 ''p(k)'' を求めるために、まず頂点の次数が <math>k</math> より大きくなる割合(累積分布関数)を求めます。次数が ''x'' より大きくなるような頂点全体の割合は、時刻 <math>t(\frac{m}{x})^2</math> より前に追加された頂点全体の割合に等しくなります。 | ||
<center> | <center> | ||
| − | <math>Pr(k_i(t) > | + | <math>Pr(k_i(t) > x) = Pr(t_i < t(\frac{m}{x})^2) = (\frac{m}{k})^2</math> |
</center> | </center> | ||
| − | 左の等号は、頂点<math>i</math> | + | 左の等号は、頂点 <math>i</math> が追加された時間 <math>t_i</math> が、時刻 <math>t</math> に対して <math>(m/k)^2</math> よりも早ければ(小さければ)、次数が <math>x</math> を超えることを示しています。 |
| − | + | 頂点が常に一定量ずつ追加されることを考えると、全体サイズを1とするなら、その割合は単純に <math>(\frac{m}{k})^2</math> としてよいことがわかります。 | |
| − | + | 次数分布 <math>Pr(k_i(t) = k)</math> は <math>Pr(k_i(t) > k) - Pr(k_i(t) > k+1)</math> と書けるので、<math> - \frac{\partial Pr(k_i(t) > k}{\partial k})</math> になります。 | |
| + | さきの答えを<math>k</math>で微分すると<math>Pr(k_i(t) = k) = 2m^2/k^3</math>。すなわち辺の次数は<math>k^{-3}</math>に比例します。 | ||
===優先的選択でない場合=== | ===優先的選択でない場合=== | ||
| − | + | 新しい辺が結びつく先が次数に比例する値ではなく、一様分布に従うと仮定してみます。 | |
<center> | <center> | ||
<math>\frac{\partial k_i}{\partial t} = m/(n-1) = m/t</math> | <math>\frac{\partial k_i}{\partial t} = m/(n-1) = m/t</math> | ||
| Line 53: | Line 79: | ||
これを解いて<math>k_i(t) = m(\log(\frac{t}{t_i})+1)</math>。こちらも累積分布関数を計算してみる。 | これを解いて<math>k_i(t) = m(\log(\frac{t}{t_i})+1)</math>。こちらも累積分布関数を計算してみる。 | ||
<center> | <center> | ||
| − | <math>P(k_i(t) > k) = P(t_i < t(1-\frac{1}{exp(k/m - 1)}) = 1-exp(1-(k/m))</math> | + | <math>P(k_i(t) > k) = P(t_i < t(1-\frac{1}{\exp(k/m - 1)}) = 1-\exp(1-(k/m))</math> |
</center> | </center> | ||
| − | これを微分すると<math>P(k_i(t)=k)=exp(-k/m)/m</math> | + | これを微分すると<math>P(k_i(t)=k)=exp(-k/m)/m</math>、すなわち辺の次数は指数的に減少することになります。 |
===何がべき分布を作るのか=== | ===何がべき分布を作るのか=== | ||
エッセンスだけ言うと、優先的選択の場合は次数の時間変化を規定する微分方程式が | エッセンスだけ言うと、優先的選択の場合は次数の時間変化を規定する微分方程式が | ||
| − | <math>\textstyle \frac{dy}{dx} = \frac{y}{2x}</math>と、<math>y</math> | + | <math>\textstyle \frac{dy}{dx} = \frac{y}{2x}</math>と、<math>y</math>が微分値の分子に現れていた点がミソになります。これを解くと<math>y=cx^{1/2}</math>という答えが得られ(<math>c</math>は適当な定数)、この係数1/2が<math>\gamma=-3</math>を作り出します。だから異なる<math>\gamma</math>の値を作り出すには<math>y/2x</math>における比の2を他にずらせればよいのです。 |
例えば | 例えば | ||
| Line 66: | Line 92: | ||
<math>\frac{\partial k_i}{\partial t} = \frac{k_i}{pt}</math> | <math>\frac{\partial k_i}{\partial t} = \frac{k_i}{pt}</math> | ||
</center> | </center> | ||
| − | という近似を何らかの形で導出すると、<math>\gamma=p-1</math> | + | という近似を何らかの形で導出すると、<math>\gamma=p-1</math>に設定できます。 |
<!---- | <!---- | ||
Revision as of 18:23, 16 April 2011
| Wiki Top | Up one level | レポートの書き方 | Arita Laboratory |
|
Scale-free性
ネットワークの頂点に接続する辺の数を次数といい、全頂点のなかで次数 k の頂点の占める割合を p(k) と書きます。
ネットワークがスケールフリーであるとは次数の分布がべき則に従うことを意味し、式で書くと
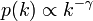 になります。
になります。
この定義は1999年の論文 Barabási A-L, Albert R "Emergence of Scaling in Random Networks" Science 286(5439):509-512 をきっかけに広まりました。
自然界にはべき則が普通に見られ、以下の例がよく知られています。(この表におけるL, Cの意味はリンク解析の項を参照。)
| Network (size) | 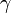 |
L | C | |
|---|---|---|---|---|
| インターネット (1.5 x 105) | 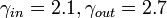 |
3.1 | 0.11 | Barabasi and Albert (1999) |
| 部分的インターネット (3000-6000) | 2.16 | 3.7 | 0.18-0.3 | Faloutous et al. (1999) |
| 映画俳優の共演関係 (2.2 x 105) | 2.3 | 3.7 | 0.79 | Watts and Strogatz (1998) |
| PubMedデータベースの共著関係 (1.5 x 106) | ? | 4.6 | 0.066 | Newman (2000, 2001) |
べき則やそれを生み出すメカニズムの解析は最近始まったものではありません。科学界ではおよそ50年周期で話題になってきました。べき則を示す有名な例として、ジップの法則、パレートの法則などがあります。
- 20世紀初頭
- Pareto, V. (1896, 1897) Cours d’economie politique. Reprinted as a volume of Oeuvres Complètes (Droz, Geneva, 1896, 1965). Pareto, V. Cours d’Economique Politique (Macmillan, Paris, 1897) 所得の分布がべき則に従うことを示す
- Yule, G. (1924) A mathematical theory of evolution, based on the conclusion of Dr. J.C. Willis. F.R.S. Phil. Trans. R. Soc. Lond Ser. B 213, 21–87 優先的選択のメカニズムを示す
- 20世紀半ば
- Zipf, G.K. (1949) Human Behavior and the Principle of Least Effort, Addison-Wesley 単語の頻度分布がべき則に従うことを示す
- Simon, H.A. (1955) On a class of skew distribution functions. Biometrika 42, 425–440 乗算過程が漸近的にべき則に従うことを示す
- 21世紀初頭
- Barabási A-L, Albert R (1999) これまでの研究をネットワークの言葉に置き換える
またべき則に近い形である対数正規分布とべき則の関係についても多くの研究がなされました。
- 乗算過程による対数正規分布の一般性
- Kapteyn, J.C. (1903) Skew frequency curves in biology and statistics in Astronomical Laboratory, Noordhoff, Groningen
- Gibrat, R. (1931) Les Inegalites Economiques, Libraire du Recueil Sirey, Paris
- 乗算過程がべき則を生むメカニズム
- Kesten, H. (1973) Random difference equations and renewal theory for products of random matrices. Acta Mathematica CXXXI, 207–248
- Reed, W.J. and Hughes, B.D. (2002) From gene families and genera to incomes and internet file sizes: why power-laws are so common in nature. Phys. Rev. E 66, 067103
Barabási-Albert Model
Barabási, Albertがネットワークの成長モデルとして提唱したのは以下の過程です。(正確には初期条件が異なるが本質は同じ。)
- 時間ステップ1において
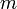 本の辺で結ばれた2頂点からスタートする。
本の辺で結ばれた2頂点からスタートする。
- 単位時間毎に頂点を1つずつ追加し、既に存在する頂点と本の辺でつなぐ。
新しい辺はそれぞれ確率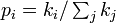 (ここで
(ここで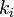 は頂点iの次数) で接続先を決定する。
は頂点iの次数) で接続先を決定する。
この過程は優先的選択(preferential attachment)と呼ばれ、一般にrich gets richerメカニズムなどともいわれます。
べき則のパラメータについて
BAモデルから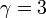 を簡単に導出できます。
初期条件として2頂点が 本のリンクで結ばれている場合、
を簡単に導出できます。
初期条件として2頂点が 本のリンクで結ばれている場合、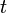 時間後には頂点数
時間後には頂点数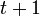 、辺数
、辺数 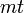 です。
頂点 i の次数 は時間が経つと単調増加します。ここで、次数を
です。
頂点 i の次数 は時間が経つと単調増加します。ここで、次数を 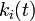 という連続関数として考えてみます。頂点 i の次数は単位時間あたり次数 に比例して増加するので
という連続関数として考えてみます。頂点 i の次数は単位時間あたり次数 に比例して増加するので
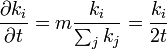
これを解くと 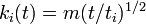 、
ただし
、
ただし 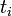 は頂点
は頂点 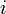 が追加された時間で
が追加された時間で 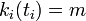 となる値です(初期条件)。
これを式変形すれば、頂点の次数がある値
となる値です(初期条件)。
これを式変形すれば、頂点の次数がある値 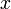 になる時間は
になる時間は 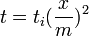 であることがわかります。
であることがわかります。
頂点の次数分布 p(k) を求めるために、まず頂点の次数が 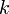 より大きくなる割合(累積分布関数)を求めます。次数が x より大きくなるような頂点全体の割合は、時刻
より大きくなる割合(累積分布関数)を求めます。次数が x より大きくなるような頂点全体の割合は、時刻 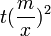 より前に追加された頂点全体の割合に等しくなります。
より前に追加された頂点全体の割合に等しくなります。
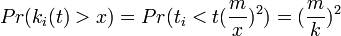
左の等号は、頂点 が追加された時間 が、時刻 に対して 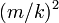 よりも早ければ(小さければ)、次数が を超えることを示しています。
頂点が常に一定量ずつ追加されることを考えると、全体サイズを1とするなら、その割合は単純に
よりも早ければ(小さければ)、次数が を超えることを示しています。
頂点が常に一定量ずつ追加されることを考えると、全体サイズを1とするなら、その割合は単純に 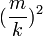 としてよいことがわかります。
としてよいことがわかります。
次数分布 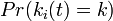 は
は 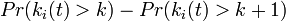 と書けるので、
と書けるので、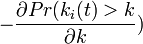 になります。
さきの答えをで微分すると
になります。
さきの答えをで微分すると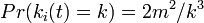 。すなわち辺の次数は
。すなわち辺の次数は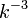 に比例します。
に比例します。
優先的選択でない場合
新しい辺が結びつく先が次数に比例する値ではなく、一様分布に従うと仮定してみます。
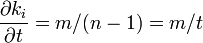
これを解いて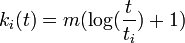 。こちらも累積分布関数を計算してみる。
。こちらも累積分布関数を計算してみる。
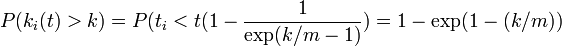
これを微分すると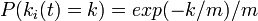 、すなわち辺の次数は指数的に減少することになります。
、すなわち辺の次数は指数的に減少することになります。
何がべき分布を作るのか
エッセンスだけ言うと、優先的選択の場合は次数の時間変化を規定する微分方程式が
 と、
と、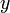 が微分値の分子に現れていた点がミソになります。これを解くと
が微分値の分子に現れていた点がミソになります。これを解くと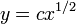 という答えが得られ(
という答えが得られ( は適当な定数)、この係数1/2が
は適当な定数)、この係数1/2が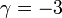 を作り出します。だから異なるの値を作り出すには
を作り出します。だから異なるの値を作り出すには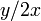 における比の2を他にずらせればよいのです。
における比の2を他にずらせればよいのです。
例えば
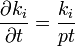
という近似を何らかの形で導出すると、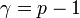 に設定できます。
に設定できます。